
ユーザーモデルは何らかの対象を想定したサンプリング調査に基づいて作られるものですから、新しい対象者の判別や予測をどのように行えばよいのか(アルゴリズム)を準備しておくことは、ユーザーモデルを活用するためには欠かせないプロセスです。
いうまでもなく、どのようなアルゴリズムを準備するかは、ユーザーモデルをビジネスでどのように活用するかを前提とする必要があります。
ちなみに、ユーザーモデルの「活用目的」は主に3つの側面で考えることができるでしょう。

人それぞれの持つ心理特性に応じてオファー(商品・サービス等)を最適化するための活用です。

何らかの特性を持つオファーに対して受容性の高い人(ターゲット)を効率的に探していくための活用です。

人それぞれの心理特性の類似度(対象に対する何らかの考え方が近いかどうか)に基づいて、人と人の間のコミュニケーションを活性化するための活用です。
判別や予測のためにどのようなアルゴリズムを準備するかを考える際には、まずはその「活用目的」を前提として…

…を設定する必要があります。
ここで、ちょっと一般的な言葉とは異なる意味合いにはなりますので、「解像度」についてもう少し掘り下げておきましょう。
「解像度」とは、“活用するために何を予測する必要があるのか”なのですが、考え方としては、図のように、おおよそ4通り想定できます。
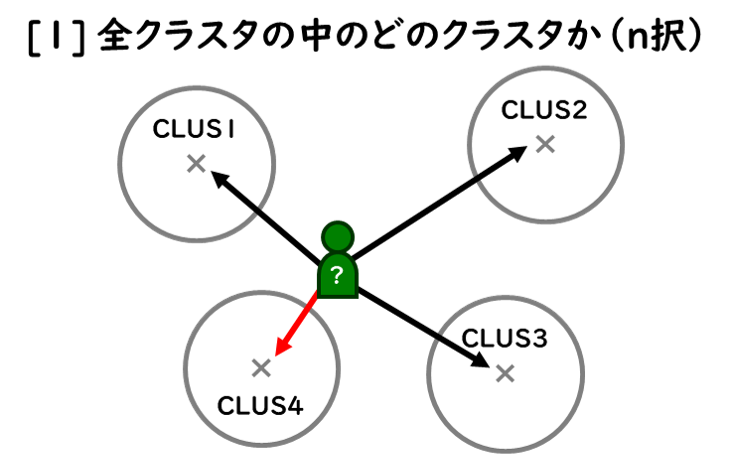
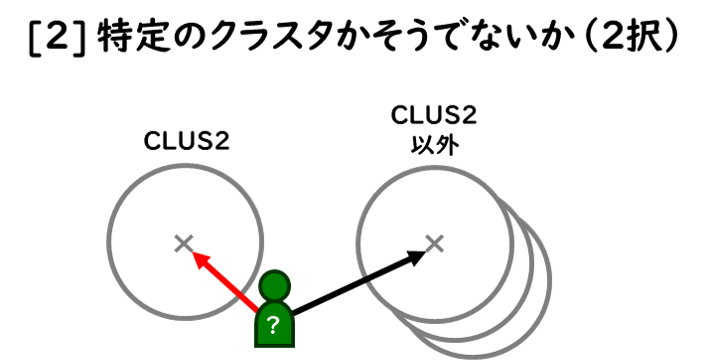
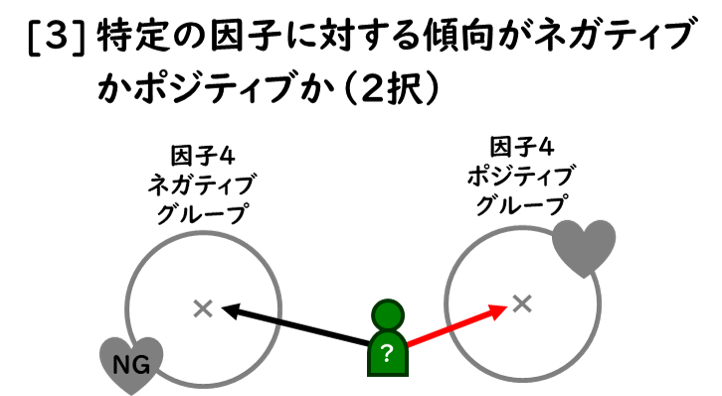
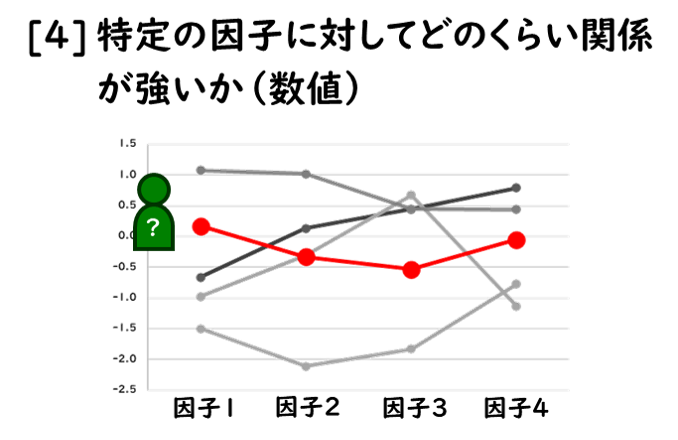
もちろん、「解像度」の考え方としては、その”組合せ”も考えられます。
”組合せ”とは、例えば、「CLUS2に所属していて、かつ因子4に対する傾向がポジティブな人」([2]と[3]の組合せ)や「CLUS1かCLUS3に所属している人の中で、因子1に対する関係の強さが上位20%の人」([1]と[4]の組合せ) …のような感じです。
また、その「活用目的」の実現に向けて判別や予測を実施する際には「状況」も想定しておく必要があります。
例えば…
「今回は予測精度はある程度我慢しても回答しやすさを優先したい…」
「見え見えになってしまうのであまりにも直接的な表現での聞き方は避けたい…」
「接客しながら使うので会話の流れに応じて少しづつ精度を上げていきたい…」
「かかりやすいバイアスはできるだけ低減したい…」
…等、様々な「状況」が考えられるでしょう。
つまり、判別や予測のためにどのようなアルゴリズムを準備するかは、まず「活用目的」を前提として…
…を設定し、その上で判別や予測を実施する場合の「状況」に応じて…

…を検討する必要がある、ということになります。
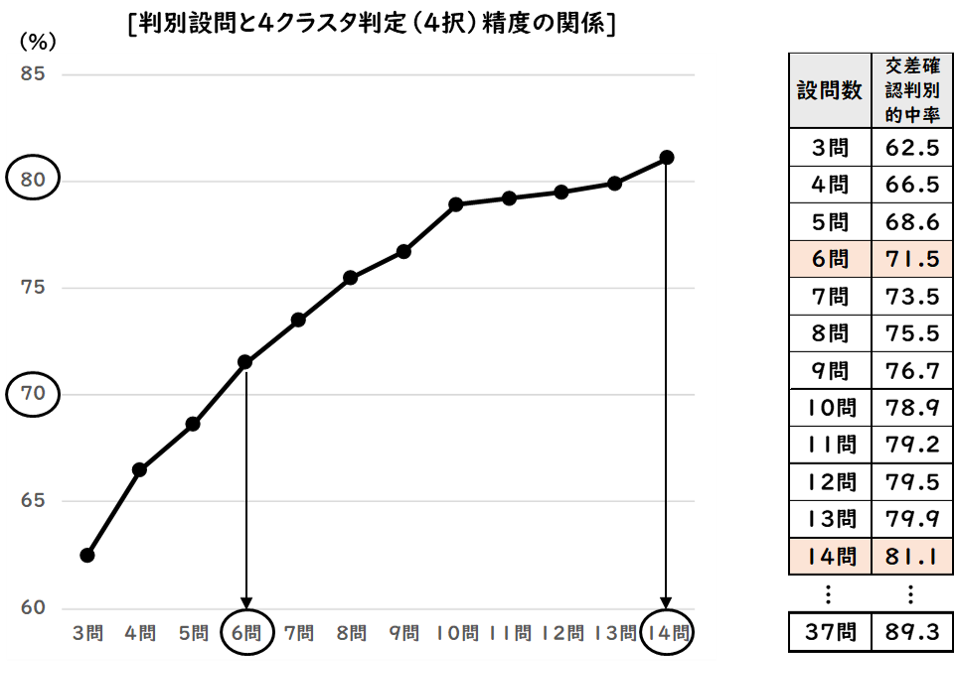
ここで、判別に使用する「変数」(設問)と「精度」について考える際には、基本的に、「使用する設問の数は多いほど精度は上がるが回答者の負担は増える」ということを認識しておく必要があります。
例えば、「消費行動傾向モデル」を前提に「モデルをあてはめてみたい対象者の所属するクラスタを判定」(4択)するための判別アルゴリズムは、37の「変数」(設問)を使用すると最大で89.3%の「精度」で予測することが可能です。
判別的中率を80%以上に保った上で最小の数の設問は「14設問」(判別的中率:81.1%)、判別的中率を70%以上に保った上で最小の数の設問は「6設問」(判別的中率:71.5%)のようになります。
以上、判別予測の考え方を整理してみると、おおよそ図のようになるでしょう。
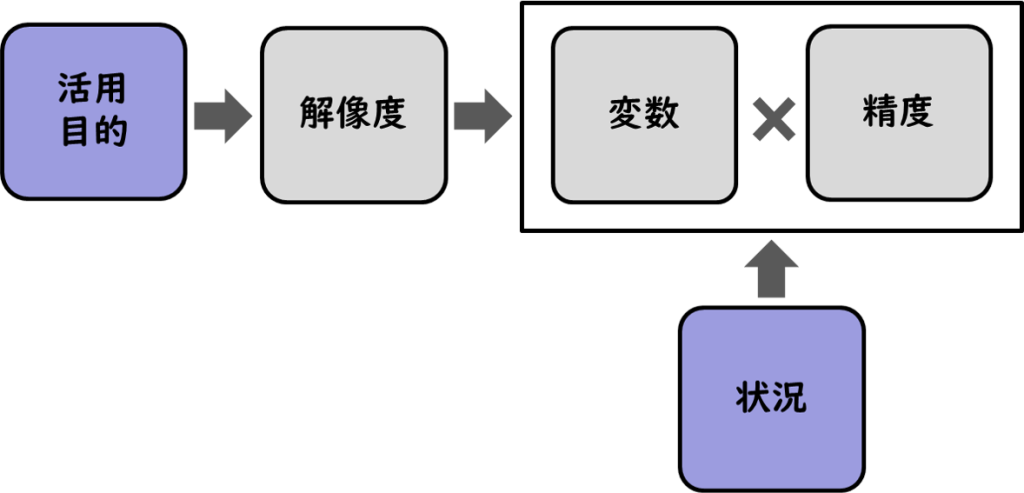
対象者のクラスタ、因子に対する傾向性や因子得点を予測するために最適な設問群はもちろんありますが、回答するのは人であり、また、ユーザーモデルを活用する目的や状況も様々です。
判別予測のアルゴリズムを考えていく際には、「活用目的」や「状況」を想定しつつ、求める(許容できる)予測(判別)「精度」と対象者に想定される負荷のバランスを考えながら、適した「解像度」を想定して「変数」(設問)を決めていく必要があるということになるでしょう。