
例えば、消費行動傾向を予測してみる
作られたユーザーモデルを使って、対象となる人の所属クラスタを予測できるようにするために、もう一つの分析を行います。
③判別分析
新しい対象者がどのクラスタに所属するのかを予測するためのアルゴリズムを作る。
例えば、下記6つの設問は、「消費行動傾向」のモデルを想定して、「対象者の所属するクラスタを予測」(4つの中のどのクラスタか)するための設問です。

これらの6つの設問に「全くそう思わない」から「とてもそう思う」の「1」~「5」で回答が得られれば、71.5%の精度で所属クラスタを予測できます。
これらの設問は「対象者のクラスタを予測(判別)するために使用する設問」という意味で「判別設問」と呼びます。
「判別設問」の数は多いほど精度は上がりますが、対象者(回答者)の負担は増えます。
「消費行動傾向」のモデルを想定したこの6つの設問は、「消費行動傾向に基づく4つのクラスタ」を作る際に回答を得た78の設問の中から、予測(判別)精度を70%以上に保った上で最小の数の設問を「判別分析」によって抽出した結果です。
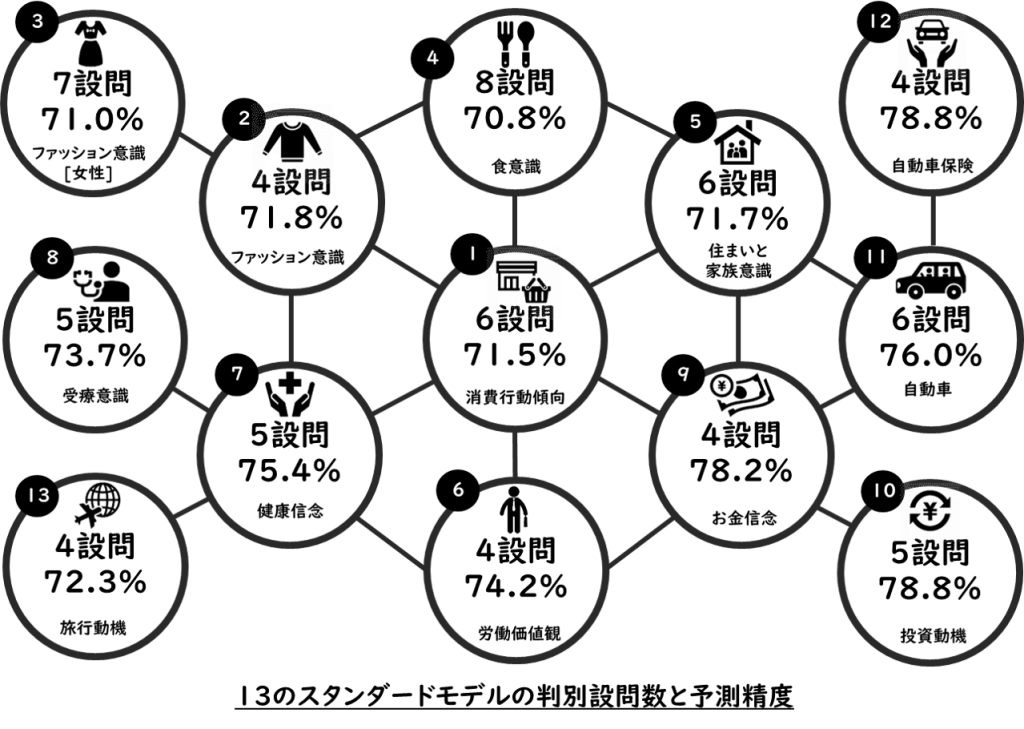
スタンダードモデルの予測
13の「スタンダードモデル」を対象に、予測精度を70~80%の範囲に保った上で最小の判別設問とその設問に対する回答結果から予測できる予測(判別)精度をそれぞれ抽出すると、以下のようになります。
※各ユーザーモデルの予測についてもう少し具体的に…は、それぞれの[ユーザーモデル名]からどうぞ。
予測問題のいろいろ
活用シーンによっては、例えば、「消費行動傾向モデル」の「何と言っても実用性重視派」(CLUS-2)の人かどうかだけ予測できれば良い場合、必ずしも「消費行動傾向モデル」の4つのクラスタの中のどこに属するかを予測(4択)する必要ななく、特定のクラスタに所属するか否かが予測(2択)できれば充分で、4択問題を2択問題にすることで対象者(回答者)の回答負荷も減ります。
また、活用シーンによっては、「消費行動傾向モデル」のどのクラスタに属するかを予測するよりも、特定の共通因子に対する傾向性(ネガティブかポジティブか) が予測できる方が効率的な場合も考えられるでしょう。
例えば…
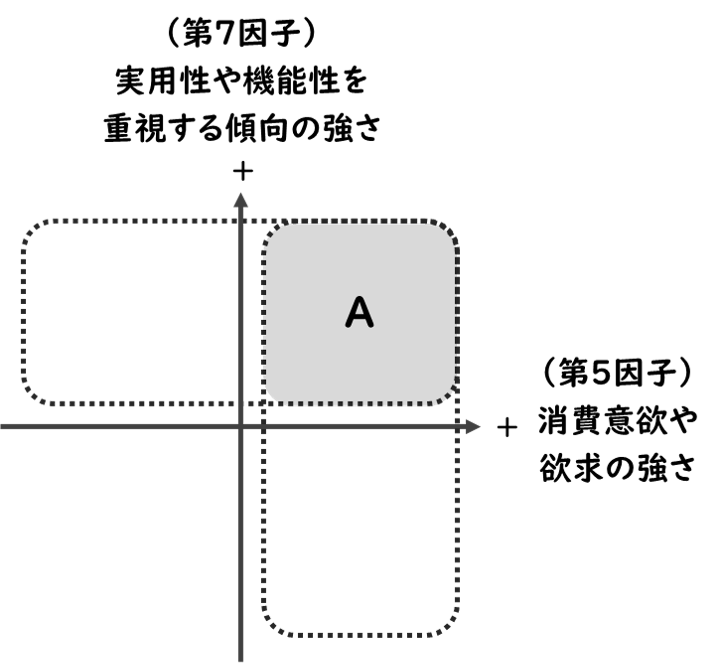
- この商品はまさに機能性を第一に考えて作ったものなので、所属クラスタはどこでも良いので、「実用性や機能性を重視する傾向の強い」(第7因子)人(ポジティブな人)に手に取ってもらいたい…
- 「消費意欲の強い」(第5因子)人(ポジティブな人)ならなお良いかも…
…であれば、所属クラスタの予測よりもAのエリアにいる人を探したいですよね。
さらに、対象者が特定の共通因子に対して「ネガティブかポジティブか」のようなグループを予測するのではなく、共通因子に対する“強さの度合い”を考慮して対象者を特定することもできます。
例えば…
- 今回のキャンペーンのプレゼントには数に限りがあるので、プレゼントを喜んでくれそうな「実用性や機能性を重視する傾向の強い」(第7因子)人の中の上位20名にだけ連絡しよう…
- ダイレクトメールは費用がかかるので、「消費意欲の強さ」(第5因子)が弱い方から30%の人には送付するのを止めよう…

共通因子に対する”強さの度合い”を抽出する場合には、判別設問への回答結果を使用することは同様ですが、予測する対象がクラスタ(CLUS-1~CLUS-4のどれか)やグループ(ネガティブかポジティブか)のようなカテゴリーではなく、“強さの度合い”という数値(因子得点)を予測する必要があるため、分析には「重回帰分析」や(予測のための)「機械学習」を使用します。