
ユーザーモデルの活用の一つに「ターゲティングの効率化」があります。
クラスタを予測することによって得られるそれぞれの人の持つ心理的な傾向性を、訴求したいオファー(商品・サービス等)の特性(特徴)を受け入れてくれる原因や動機と親和性がある人を特定するために活用することで、オファーに対する受容性の高い人を効率的に探していくための活用です。
但し、同一のクラスタに所属するということは、総合的には他のクラスタよりもそのクラスタに近い、ということにすぎず、同じクラスタに所属する人が全く同じ心理特性を有しているわけではありません。
例えば、「消費行動傾向モデル」を判定するための6つの設問に[4,2,4,3,1,2]と回答したA、[4,1,2,3,2,3]と回答したB、[4,2,2,4,2,2]と回答したCは、共にクラスタ2と判定(判別的中率:71.5%)されますが、A/B/Cに個別に予測された因子得点(赤線)と判定されたクラスタ2の因子得点平均値(グレー線)を比べてみると、それぞれ少しづつ特性が異なりそうです。
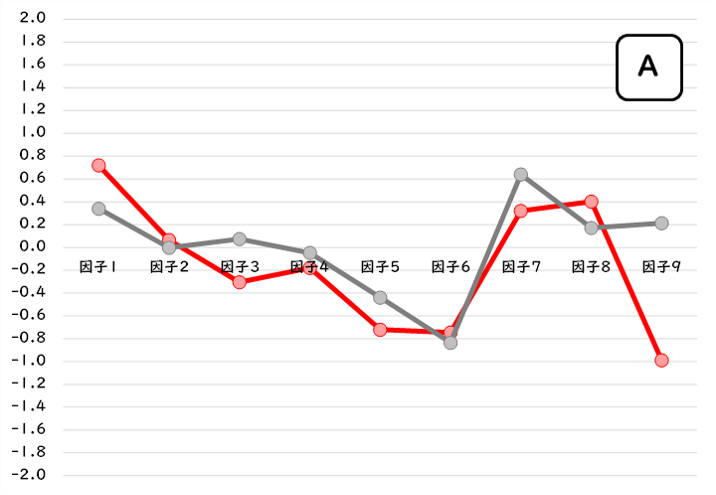

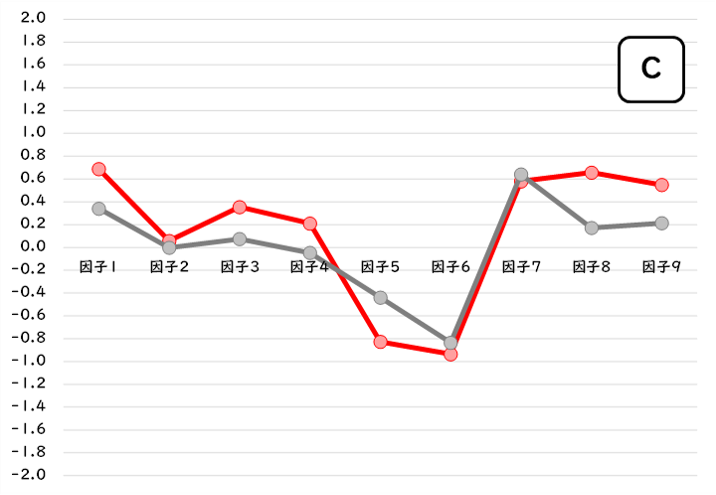
では、どのサンプルが最も典型的なクラスタ2の心理特性をもっているといえるでしょうか。
チャートを見ただけではちょっとわかりにくいので、クラスタ2の因子得点平均値とA/B/Cに個別に予測された因子得点を、コサイン類似度(※)で比べてみると…
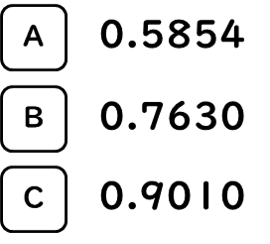
…となり、クラスタ2の因子得点平均値と最も類似した因子得点を保有したサンプルを典型的なクラスタ2のサンプルと考えるならば、「Cが最も典型的で、次にBが典型的なクラスタ2のサンプルである」といえそうです。
典型的なクラスタ2を対象にした施策の対象者としてプライオリティを付けてレコメンドするならば…

…の順となるでしょう。
また、レコメンドに協調フィルタリングを活用している人は多いと思います。
協調フィルタリングが購買履歴の類似度に基づいて似ているユーザーを抽出して、似ているユーザーが購入している商品をレコメンドするように、ユーザーモデルを活用して、心理特性の類似度に基づいて似ているユーザーを抽出し、心理特性の似ているユーザーが購入している商品をレコメンドするようなことも可能になります。
今度は、クラスタ2の因子得点平均値とではなく、サンプルA/B/Cに予測された因子得点のそれぞれをコサイン類似度で比べてみましょう。
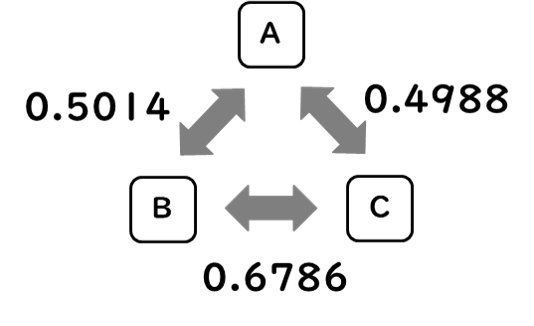
直接サンプルA/B/Cの因子得点を比べてみると、Bの心理特性に近いのはAよりC、Aの心理特性に近いのはCよりB…といったことがわかりますから、例えば、「BにレコメンドするならCの購入した商品を、AにレコメンドするならどちらかといえばBの購入した商品を」…といった感じになるでしょう。
(※)コサイン類似度とは、 2本のベクトルがどれくらい同じ向きを向いているのか(似ているのか)を表す値(-1以上~1以下)で、対象間の類似度を測る指標として使われます。