
例えば、「消費行動傾向モデル」を前提に、ある200サンプルの所属クラスタを判別設問を使って判定した結果、下記のような結果が得られたとしましょう…
クラスタ1に所属する人は47人(23.5%)となっています。

「消費行動傾向モデル」に基づく4つのクラスタ毎の各因子に対する傾向性については、それぞれ下記のような「因子得点平均値」(共通成分の量)を保有していますから、例えば、クラスタ1の人の第1因子(明るく開放的な傾向の強さ)に対する傾向に注目すると…
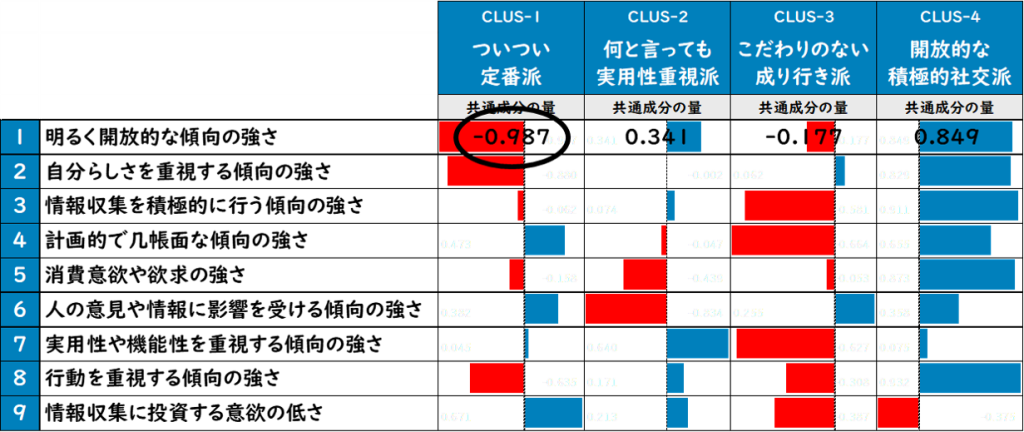
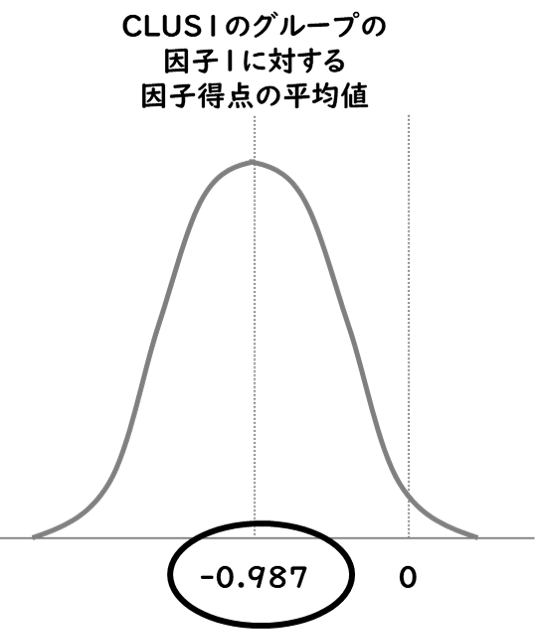
クラスタ1の47人の第1因子に対する傾向性は、所属クラスタを判定するだけで、「因子得点平均値」から、まずは全員-0.987(結構ネガティブ)と考えることができます。
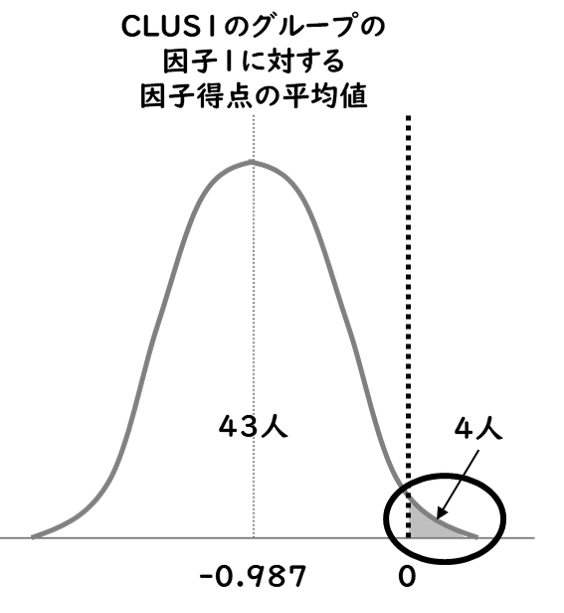
但し、クラスタ1の47人の第1因子の因子得点の平均は-0.987となりますが、クラスタ1と判定された47人の第1因子に対する「ネガポジ」を直接判定(※1)してみると、ネガティブゾーンに43人、ポジティブゾーンに4人いることが判ります。
第1因子に対する傾向性を使って施策の判断をしたいのであれば、確かにクラスタ1の人は平均的には他のクラスタの人よりも第1因子に対してはネガティブではありますが、同じクラスタ1ではあっても、この4人はポジティブに含めて考えたいところでしょう。
(※1)所属クラスタの判定を想定した6設問をステップワイズ方式で投入、各因子に対する因子得点の「ネガ」「ポジ」の2群の判別分析を実施、抽出された5問によって判定。
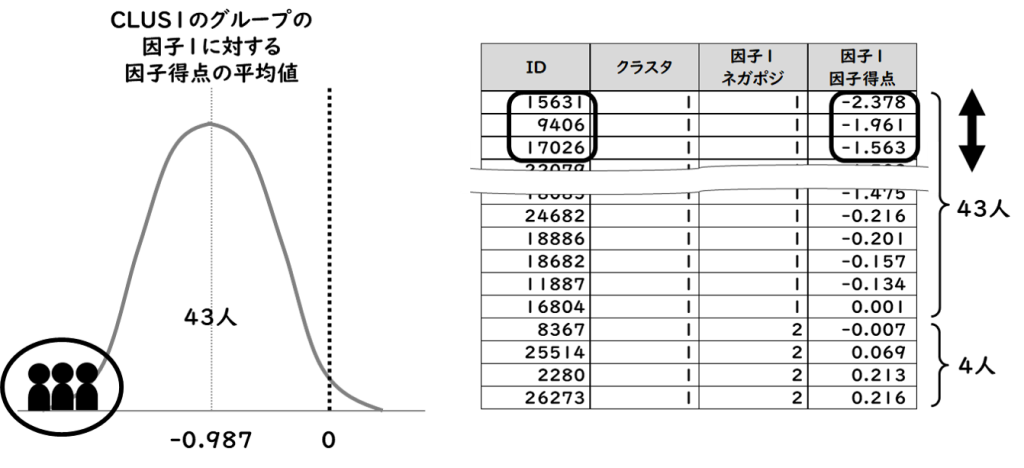
さらに、クラスタ1の47人のうちネガティブゾーンには43人いますが、第1因子に対する「因子得点」を直接予測(※2)して、その度合いの強さで並べてみると、例えば、“ネガティブな度合いの強い人から3人選ぶなら、15631/9406/17026を選択しよう“、といったことも可能になります。
(※2)所属クラスタの判定を想定した6設問をステップワイズ方式で投入、各因子に対する因子得点を重回帰分析を使って予測。
判定されたユーザーモデルの解像度をより高めるためにクラスタを構成する因子に対する傾向性を活用するのは大切です。
同じ所属クラスタと判定されたとしても、判別設問への回答が全て同じわけではないので、当然回答者それぞれに特徴は異なります(他のクラスタよりは判定されたクラスタに近いというだけですから)。
また、所属クラスタを判定するための判別設問の範囲であれば、所属クラスタの判定と同時に対象者それぞれの因子に対する傾向性(「ネガ」「ポジ」や因子得点)を予測することも可能ですから、回答の負荷をかけることなく解像度を高めることが可能になります。
もちろん因子に対する傾向性の判定や予測の精度は因子によってそれぞれですから、活用できるかどうかは状況によって判断する必要はありますが、複雑な人の気持ちの理解の解像度を高め、オファーや施策を適切に適合させるための一つの考え方になるでしょう。